


V100 + Power: GPUs on the Cheap
Affordable and scalable, what more can you ask for?

One of the cool things IBM does is buy back depreciated hardware, refurbish it, and resell it for a fraction of the original price. For an HPC system, you can build large systems out of old hardware, so this can be a great value, because a refurb IBM Power system is as good as new, meaning it will run for years and years without giving you any headaches.
Back in the heady days of NVIDIA’s big push into the commerical HPC space, IBM released a GPU-accelerated Power9 server, the AC922. These servers were built for HPC scalability and leveraged the supercomputing expertise of IBM engineers. They have twice as much NVLink bandwidth as DGX systems from NVIDIA, 100 Gb Infiniband, and 4 cards per server in the 2U air-cooled version. You might be asking, why not eight, like in a DGX? IBM plays conservative with heat, building a much larger safety factor into its systems than other vendors. Plus, too many cards in a server means the network gets overburdened, and the system doesn’t scale. That’s why Summit and Sierra, the AC922-powered supercomputers, have rock-solid reliability, consistent performance, and whole-system scalability. Reliability matters - in less than 60 days, 1 in every 100 GPUs in Meta’s massive DGX cluster failed. By contrast, in seven years across roughly 10,000 GPU servers in Summit and Sierra, there have been very, very few failures.
But is it really worth it? These things are almost seven years old. Should you really consider a 7-year-old system? Well, how do we even get an apples-to-apples comparison. Let’s just go by rack space. An H100 DGX system is a massive 8U box, and we can put four AC922s in the same space.
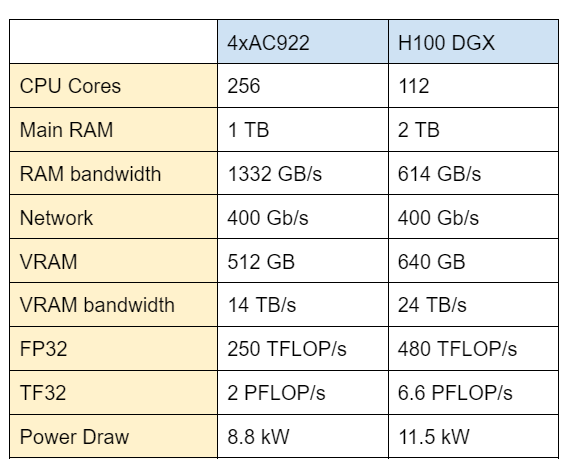
We can see that, depending on the workload, the H100 DGX should be about 2x-3x faster…well, unless you need CPU power, then the fact that our venerable old V100 system has 64 channels of DDR4 provides a lot more total system bandwidth than the DGX’s 16 channels of DDR5. But we should expect the DGX to be faster, right? If the 5nm H100 chip wasn’t able to deliver more compute per watt and per volume than the 12nm V100 chips, something would be very, very wrong.
But now let’s talk dollars and cents. The list price I can find on an H100 DGX, even today, is over $400,000. With Google and Meta buying them by the shipping container, prices remain high. Now let’s talk total cost of ownership. These sytems aren’t quite the same, so let’s say you’re looking at either 8xAC922 or a single H100 DGX. The DGX is faster, but the 8xAC922 system has more capacity and a lot more CPU performance. So, assuming 5-year asset depreciation, and all energy and floorspace costs rolled up at $0.50 per kW-hr ($360 per kW-month) and assuming 100% utilization (overestimating energy use favors the more efficient system), we can do the following calculations:

So I can work backward and figure that to get an equiavlent deal on 8xAC922s just in terms of price per performance, I need to pay a total of $268,260 for them, or about $33,532 per AC922 server. Of course, there are some hidden costs to the NVIDIA system…every time a component fails, that’s going to cost you in terms of lost work. Server downtime gets expensive real fast.
I’m not going to publish a quote in a blog post, but you see the subtitle? If you want affordable and scalable…
…call me. Or email me:
info@tachos-hpc.com