


Vectorizing Your Code - Jacobi Iteration

With the immense bandwidth of IBM Power10 with OMI-DDR5 (up to 1.2 TB/s) it’s more important than ever to understand how to vectorize code without having to rewrite every last line with intrinsics. Of course, this isn’t just applicable to Power10. In fact, I learned all these tricks when developing for Intel’s Haswell architecture back in the old days. Although EPYC and Xeon processors don’t have as much bandwidth as Power10, vectorizing your code will still enable you to run as fast as possible on lower core counts, lowering the total cost of ownership for anyone running your code.
Here’s a simple step of Jacobi iteration (code):

Now, this looks pretty trivially vectorizable, since it’s just loops over arrays and basic arithmetic. Some compilers will vectorize this, but it depends on the version and the platform. For x86, gcc 14.2 will only use basic movss and mulss functions if we use -march=x86-64-v2, but will use the AVX-based vmovss and vmulss if we tell it to use -march=x86-64-v4. Clang will be even more aggressive with x86-64-v4. Now, if we look at gcc 14.2 compiling for power64le, it just uses scalar and fused multiply-add instructions:

We want it to use vector instructions, so let’s give it some help. Reasoning about this loop, the compiler doesn’t actually know that the array it’s given has more than zero elements, so maybe it needs some help to guarantee there are loops of at least 4 32-bit floats so its 128-bit SIMD units can stay busy.
First, we’ll add the “__restrict__” keyword to the pointers. The compiler doesn’t actually know if what we’re reading from and writing to are the same memory addresses. They could be, and “__restrict__” tells the compiler that we pinky-swear that “float* x_new” won’t point to any of the memory we’re reading from.

This changes the resulting assembly quite a bit. By letting the compiler know it’s not going to write where it reads, the inner loop over neighbors is now using the vector instruction, xvmulsp. However, the last part of the loop, where we multiply by the inverse (sorry, bad variable name) diagonal, is still scalar:
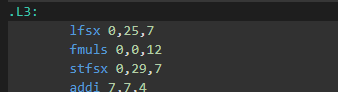
See, fmuls is a single-precision scalar multiply. I don’t like that, do you?
Let’s suppose now that require the input x_new and x_old to have a length divisible by four (32 x 4 = 128). That is, even if the matrix has an odd number of entries, it has to be padded by a few elements. This should be no big deal - we probably have tens of thousands of floats to churn through; an extra two or three is no big deal.
So now we have a big outer loop plus an inner loop of exactly four elements. Surely the compiler will vectorize this!

When I look at the assembly, the last part of the loop, the part most intuitively vectorizable, is still not vectorized. Maybe if I make each operation look like a vector operation, the compiler will finally get with the program (code):

Finally! This worked! The assembly for the last line reveals the coveted xvmulsp instruction. But now I am in a real pickle. I ended up having to through the entire loop and rewrite it so the compiler would pick up things that seemed obvious to me. If I’m working on a production code base with thousands of legacy loops that each need to be refactored — notice I avoided using intrinsics entirely — I could be working for a very, very long time.
Now, this might be overkill at this point. The fact is, the compiler vectorized some substantial chunks of this loop. But hey, we’re having fun, so let’s see just how far we can go. The last thing we’re going to do is use Altivec intrinsics and assume that inner loop is padded (and that I’m not getting a dangling reference). Since our SIMD width is 4, and we’ll always have at least 4 elements in a row (such as with tet meshes), it probably is worth it.
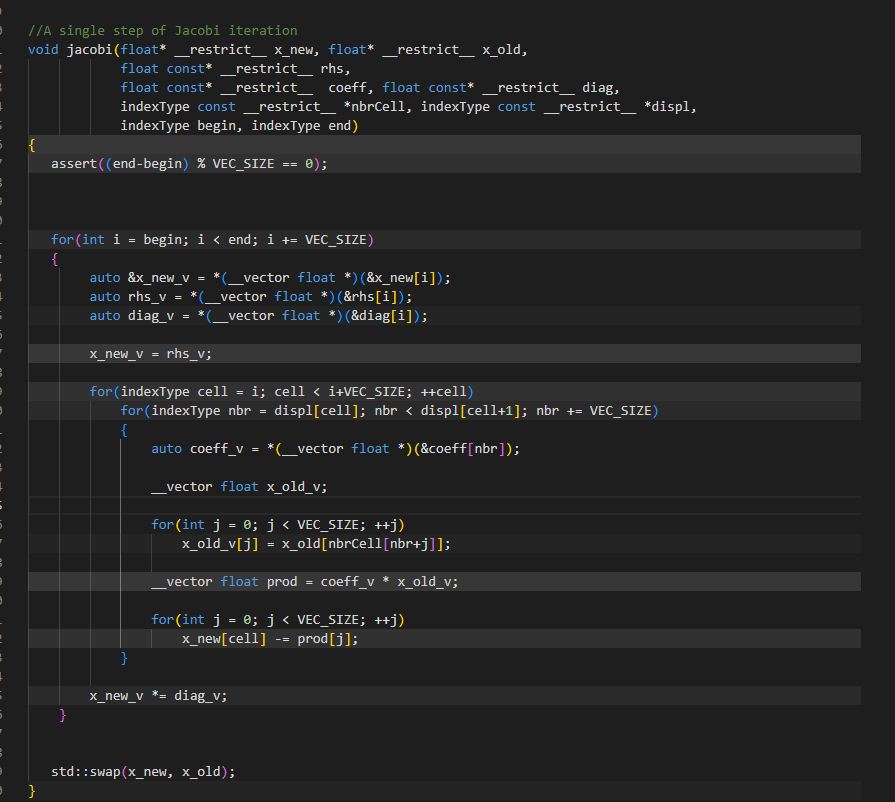
Now, the skilled C++ programmer will probably ask why I don’t build some machinery to create vector types on the fly, and the answer is, “I didn’t feel like messing with decltype and type traits to make it all work.” But let’s look at what I did here. I used the Altivec intrinsic type, “__vector float” to create what are basically arrays that have overloaded operators (these work in pure C as well).
The x_old values are all over the place in memory, so I gathered them into a local vector, x_old_v. While the Power ISA doesn’t have a vector-gather, there’s a supplemental library on github that has tons of useful extensions. Check it out.
Of course, anyone who has written production code will realize that this code isn’t portable at all. What you would want to in real life is encapsulate the intrinsics in a set of classes and template functions so that you use the desired functions depending on what platform you’re compiling for. I didn’t fill out the machinery (I used some dummy functions to get rid of red squiggles, as managing C++ types can be tricky), but this is the idea:

It’s not 100% production-ready, but the shape is starting to look right to me. Of course, in reality, we’d want to do some careful benchmarking to ensure our optimizations really were delivering performance improvements (Godbolt doesn’t really have ample Power10 benchmarking facilities).
In the end, vectorizing your code is a little tricky, but it’s not as daunting as it first seems to be when you start wading through the documentation of intrinsics. The real trick is the same you come across in many programming tasks - find the right abstractions so you don’t make a mess.
I don’t have a Power10 CPU to run on at the moment, but I’d like to give this code a try and see what benefits I can really get - proof’s always in the pudding.
If you’re interested in Power10 solutions for your computational needs, contact us at info@tachos-hpc.com.